پاکسازی داده ها و انتخاب ویژگی (وظایف مشترک اماده سازی داده)

پاکسازی داده ها
پاکسازی داده ها شامل رفع مشکلات سیستماتیک یا خطاها در داده های نامرتب است. مفیدترین پاکسازی داده ها شامل تخصص عمیق حوزه است و می تواند شامل شناسایی و رسیدگی به مشاهدات خاصی باشد که ممکن است نادرست باشند. دلایل زیادی وجود دارد که داده ها ممکن است مقادیر نادرستی داشته باشند، مانند اشتباه تایپ شدن، خراب شدن، تکراری بودن و غیره. تخصص دامنه ممکن است اجازه شناسایی مشاهدات اشتباه آشکار را بدهد، زیرا با آنچه انتظار می رود متفاوت است، مانند قد 200 فوتی یک فرد.
هنگامی که مشاهدات آشفته، پر سر و صدا، فاسد یا اشتباه شناسایی شدند، می توان به آنها رسیدگی کرد. این ممکن است شامل حذف یک ردیف یا یک ستون باشد. به طور متناوب، ممکن است شامل جایگزینی مشاهدات با مقادیر جدید باشد. به این ترتیب، عملیات کلی پاکسازی داده وجود دارد که می توان انجام داد، مانند :
• استفاده از آمار برای تعریف داده های عادی و شناسایی نقاط پرت
• شناسایی ستون هایی که دارای مقدار یکسان یا بدون اختلاف هستند و حذف آنها
• شناسایی ردیف های تکراری داده ها و حذف آنها
• علامت گذاری مقادیر خالی به عنوان گمشده
• وارد کردن مقادیر از دست رفته با استفاده از آمار یا یک مدل آموخته شده
پاکسازی داده ها عملیاتی است که معمولاً ابتدا قبل از سایر عملیات آماده سازی داده ها انجام می شود
انتخاب ویژگی
انتخاب ویژگی به تکنیک هایی برای انتخاب زیرمجموعه ای از ویژگی های ورودی اشاره دارد که بیشترین ارتباط را با متغیر هدف پیش بینی شده دارد. این مهم است زیرا متغیرهای ورودی نامربوط و زائد می توانند الگوریتم های یادگیری را منحرف یا گمراه کنند که احتمالاً منجر به عملکرد پیش بینی کمتر می شود. علاوه بر این، توسعه مدلها تنها با استفاده از دادههایی که برای انجام یک پیشبینی لازم است، مطلوب است، به عنوان مثال. ساده ترین مدل ممکن با عملکرد خوب را ترجیح دهید.
تکنیک های انتخاب ویژگی ممکن است به طور کلی به آنهایی که از متغیر هدف (با نظارت) استفاده می کنند و آنهایی که استفاده نمی کنند (بدون نظارت) گروه بندی شوند. علاوه بر این، تکنیکهای نظارت شده را میتوان به مدلهایی تقسیم کرد که بهطور خودکار ویژگیها را به عنوان بخشی از برازش مدل (ذاتی) انتخاب میکنند، آنهایی که به صراحت ویژگیهایی را انتخاب میکنند که منجر به بهترین مدل میشوند (wrapper) و مدلهایی که به هر ویژگی ورودی امتیاز میدهند و اجازه میدهند زیر مجموعه ای که باید انتخاب شود (filter).
روش های آماری، مانند همبستگی، برای امتیازدهی ویژگی های ورودی محبوب هستند. سپس ویژگیها را میتوان بر اساس امتیازات و زیرمجموعهای با بیشترین امتیازها به عنوان ورودی یک مدل رتبهبندی کرد. انتخاب معیارهای آماری به انواع دادههای متغیرهای ورودی بستگی دارد و مروری بر معیارهای آماری مختلفی که میتوان استفاده کرد در فصل 11 معرفی شده است. مانند:
• ورودی های دسته بندی شده برای متغیر هدف طبقه بندی .
• ورودی های عددی برای متغیر هدف طبقه بندی .
• ورودی های عددی برای متغیر هدف رگرسیونی .
هنگامی که مخلوطی از انواع داده های متغیر ورودی وجود دارد، می توان از روش های فیلتر مختلف استفاده کرد. متناوبا، می توان از یک روش پوششی مانند روش محبوب حذف ویژگی بازگشتی ((RFE استفاده کرد که نسبت به نوع متغیر ورودی agnostic است .حوزه وسیع تر امتیاز دهی به اهمیت نسبی ویژگیهای ورودی به عنوان اهمیت ویژگی نامیده میشود و بسیاری از تکنیکهای مبتنی بر مدل وجود دارند که خروجیهای آنها میتواند برای کمک به تفسیر مدل، تفسیر مجموعه دادهها یا در انتخاب ویژگیها برای مدلسازی مورد استفاده قرار گیرد.
مطالب زیر را حتما بخوانید:

اثر متقابل
اثر متقابل در مورد فرضیاتی که ممکن است در این شرایط انجام دهید بسیار محتاط باشید. برای مثال، برای یک توسعهدهنده غیرمعمول نیست که ببیند «http://some.url.2» «همیشه» بسیار کندتر از...
جزییات بیشتر
دیکشنری های فقط خواندنی
دیکشنری های فقط خواندنی MappingProxyType یک بسته بندی در اطراف یک فرهنگ لغت استاندارد است که یک نمای فقط خواندنی به داده های فرهنگ لغت پیچیده ارائه می دهد. کلاس...
جزییات بیشتر
فرم ها در بوت استرپ (2)
عناصر و اجزای فرم ها - ناحیه متن زمانی استفاده می شود که به چندین خط ورودی نیاز دارید پیدا کنید که شما عمدتاً میتوانید ویژگی ردیفها را تغییر میدهید،...
جزییات بیشتر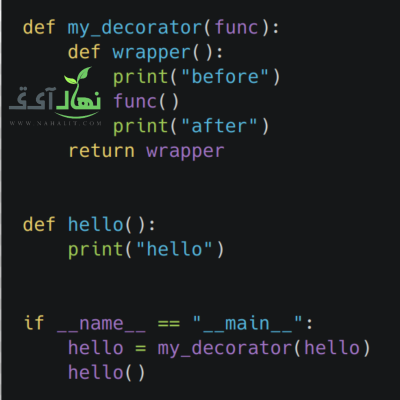
دکوراتورها می توانند رفتار را اصلاح کنند
اکنون که کمی با نحو دکوراتور آشنا شدید، بیایید دکوراتور دیگری بنویسید که در واقع کاری انجام می دهد و آن را اصلاح می کند در اینجا یک دکوراتور کمی...
جزییات بیشتر
چک لیست املاک و مستغلات صفحه وب
اندازه مرورگر خود را به 1024x768 تغییر دهید و ببینید چه چیزی در بالای صفحه بارگذاری می شود.آیا محتوای مفیدی وجود دارد؟آیا تبلیغات خیلی زیاد است؟اگر تبلیغات بسیار زیادی...
جزییات بیشتر
تایپ کردن.NamedTuple – Namedtuples بهبود یافته
تایپ کردن.NamedTuple – Namedtuples بهبود یافته کلاس namedtuple در ماژول مجموعه ها.21 بسیار شبیه به namedtuple است، تفاوت اصلی آن یک نحو به روز شده برای تعریف انواع رکوردهای جدید...
جزییات بیشتر
خط فکری
خط فکری همانطور که به نظر مضحک می آید برای اینکه چگونه روز خود را برنامه ریزی می کنیم و فکر می کنیم که چه کاری انجام دهیم و به...
جزییات بیشتر
چالش های جامعه اطلاعاتی
حال به ذکر چالشهایی که باظهور جامعه اطلاعاتی با آن روبهرو خواهیم شد، می پردازیم.چالشـهاي ناشی از جامعه اطلاعاتی موارد زیر می باشند: نابرابري اجتماعی: در بحث برابري یـا نـابرابري...
جزییات بیشتر
حلقه رویداد چیست؟
حلقه رویداد چیست؟ یک حلقه به طور مداوم در حال اجرا وجود دارد که با حلقه while نشان داده می شود، و هر تکرار این حلقه یک "تیک" نامیده می...
جزییات بیشتر
ترفندهای برش و سوشی را فهرست کنید
ترفندهای برش و سوشی را فهرست کنید اشیاء لیست پایتون یک ویژگی منظم به نام برش دارند. می توانید مشاهده کنید آن را به عنوان یک فرمت از نحو نمایه...
جزییات بیشتر
چک لیست نظرات
چک لیست نظرات آیا وب سایت شما دارای بخش نظرات است که بازدیدکنندگان می توانند نظرات، افکار و سؤالات خود را در آنجا مطرح کنند؟ آیا وب سایت شما فرم...
جزییات بیشتر
دیکشنری ها، نقشه ها و هشتبل ها
دیکشنری ها، نقشه ها و هشتبل ها در پایتون، دیکشنری ها (یا به اختصار «Dicts») یک ساختار داده مرکزی هستند. دیکت ها تعداد دلخواه شی را ذخیره می کنند که...
جزییات بیشتر
قوانین ارسال دیدگاه در سایت