شناسایی و حذف موارد پرت

هنگام مدلسازی، تمیز کردن نمونه دادهها برای اطمینان از اینکه مشاهدات به بهترین شکل مشکل را نشان میدهند، مهم است. گاهی اوقات یک مجموعه داده می تواند حاوی مقادیر شدیدی باشد که خارج از محدوده مورد انتظار و بر خلاف سایر داده ها هستند. به این موارد پرت گفته میشود و اغلب مدلسازی یادگیری ماشین و مهارت مدلسازی به طور کلی میتواند با درک و حتی حذف این مقادیر پرت بهبود یابد. در این آموزش، موارد پرت و نحوه شناسایی و حذف آنها را از مجموعه داده های یادگیری ماشین خود کشف خواهید کرد. پس از تکمیل این آموزش، خواهید دانست :
• اینکه یک نقطه دور از یک مشاهده غیر محتمل در یک مجموعه داده است و ممکن است یکی از دلایل متعدد داشته باشد.
• نحوه استفاده از آمارهای تک متغیره ساده مانند انحراف استاندارد و محدوده بین چارکی برای شناسایی و حذف مقادیر پرت از نمونه داده.
• نحوه استفاده از یک مدل تشخیص پرت برای شناسایی و حذف ردیفها از مجموعه داده آموزشی به منظور افزایش عملکرد مدلسازی پیشبینیکننده.
6.1 مرور کلی آموزش
این آموزش به پنج بخش تقسیم شده است. شامل:
1. Outliers چیست؟
2. مجموعه داده ها را آزمایش کنید
3. روش انحراف استاندارد
4. روش محدوده بین ربعی
5. تشخیص خودکار نقاط بیرونی
6.2 Outliers چیست؟
پرت، مشاهده ای است که بر خلاف مشاهدات دیگر است. آنها نادر، متمایز هستند یا به نحوی مناسب نیستند.
• ما به طور کلی نقاط پرت را به عنوان نمونه هایی تعریف می کنیم که به طور استثنایی از جریان اصلی داده ها فاصله دارند.
پرت می تواند دلایل زیادی داشته باشد، مانند:
• اندازه گیری یا خطای ورودی.
• خرابی داده ها.
• مشاهدات پرت واقعی.
به دلیل ویژگی های هر مجموعه داده، راه دقیقی برای تعریف و شناسایی نقاط پرت به طور کلی وجود ندارد. در عوض، شما یا یک متخصص حوزه، باید مشاهدات خام را تفسیر کنید و تصمیم بگیرید که آیا یک مقدار یک مقدار پرت است یا خیر.
• حتی با درک کامل داده ها، تعریف نقاط پرت ممکن است دشوار باشد. باید بسیار دقت کرد که عجولانه مقادیر را حذف یا تغییر ندهید، به خصوص اگر حجم نمونه کوچک باشد.
با این وجود، میتوانیم از روشهای آماری برای شناسایی مشاهداتی استفاده کنیم که با توجه به دادههای موجود، نادر یا بعید به نظر میرسند.
• شناسایی داده های پرت و بد در مجموعه داده شما احتمالاً یکی از دشوارترین بخش های پاکسازی داده ها است و درست کردن آن زمان می برد. حتی اگر درک عمیقی از آمار و چگونگی تأثیر عوامل پرت بر دادههای شما داشته باشید، همیشه موضوعی است که باید با احتیاط آن را بررسی کنید.
این بدان معنا نیست که مقادیر شناسایی شده پرت هستند و باید حذف شوند. اما، ابزارهایی که در این آموزش توضیح داده شده اند، می توانند برای روشن کردن رویدادهای نادری که ممکن است نیاز به نگاهی دوباره داشته باشند، مفید باشند. یک نکته خوب این است که ترسیم مقادیر پرت شناسایی شده را در نظر بگیرید، شاید در زمینه مقادیر غیر پرت برای دیدن اینکه آیا رابطه یا الگوی سیستماتیکی با مقادیر پرت وجود دارد یا خیر؟ اگر وجود داشته باشد، شاید آنها پرت نباشند و بتوان آنها را توضیح داد، یا شاید خود پرت ها را بتوان به طور سیستماتیک تری شناسایی کرد.
مطالب زیر را حتما بخوانید:

دام های متغیر کلاس در مقابل نمونه
دام های متغیر کلاس در مقابل نمونه علاوه بر ایجاد تمایز بین متدهای کلاس و نمونه متغیرهای نمونه روشها، مدل شی پایتون نیز بین کلاس و این یک تمایز مهم...
جزییات بیشتر
7 روند UX که باید از آنها آگاه بود (بخش سوم)
تجربه فراگیرای کاش محصولات بیشتری با این روند UX مطابقت داشتند زیرا بر مفهوم دسترسی برای همه کاربران بدون توجه به زمینه متمرکز است. متأسفانه، بیشتر محصولات به یک اندازه...
جزییات بیشتر
دامنه های پر شده با کلمه کلیدی
یکی دیگر از مشکلات احتمالی نام دامنه، پر کردن کلمات کلیدی است.فرض کنید وب سایت شما در حال فروش لنزهای تماسی آرایشی است.اگر دامنه شما cosmetic-halloween-colored-contact-lenses.com بود، واضح است که...
جزییات بیشترتایپو گرافی و Heading در بوت استرپ
پوشه بندی بوت استرپ زمانی که بوت استرپ را دانلود میکنیم شامل سه فلدر است سی اس اس و جی اس و ایمیج. برای سادگی انها را به پروژه روتمان...
جزییات بیشتر
انجام در مقابل برنامه ریزی
انجام در مقابل برنامه ریزی خوب، بنابراین مغز ما را میتوان مانند روشهایی در صف حلقه رویداد تک رشتهای در نظر گرفت، مانند موتور JS. به نظر می رسد مسابقه...
جزییات بیشتر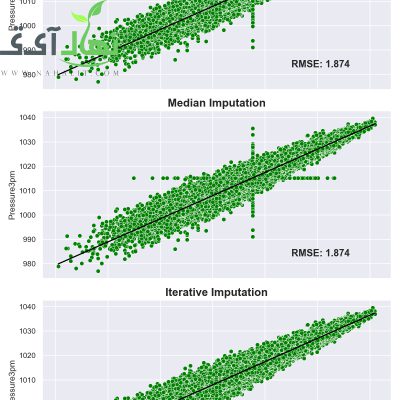
ادامه انتساب تکراری (Iterative Imputation) و مجموعه داده کولیک اسب
ادامه انتساب تکراری (Iterative Imputation) انتساب تکراری به فرآیندی اشاره دارد که در آن هر ویژگی به عنوان تابعی از ویژگی های دیگر مدل می شود، به عنوان مثال. یک...
جزییات بیشتر
مقایسه اشیاء: “is” در مقابل “==”
وقتی من بچه بودم، همسایه های ما دو گربه دوقلو داشتند. به نظر می رسید که آنها کاملاً یکسان به نظر می رسیدند - همان خز زغالی و همان رنگ...
جزییات بیشتر
علامت گذاری مقادیر از دست رفته(نحوه علامت گذاری و حذف داده های از دست رفته)
علامت گذاری مقادیر از دست رفته بیشتر داده ها دارای مقادیر گم شده هستند و احتمال وجود مقادیر از دست رفته با اندازه مجموعه داده افزایش می یابد. • داده...
جزییات بیشتر
ایمیل ها
این به خوبی با موضوع فروش مرتبط است. اگر اتفاقا فروش داریدنیرویی که متکی بر ارسال ایمیل به مشتریان احتمالی و مشتریان استدر روزهای قبلی ،CRM می توانستید ایمیلی را...
جزییات بیشتر
دیکشنری ها، نقشه ها و هشتبل ها
در پایتون، دیکشنری ها (یا به اختصار «Dicts») یک ساختار داده مرکزی هستند. دیکت ها تعداد دلخواه شی را ذخیره می کنند که هر کدام با a مشخص می شوند...
جزییات بیشتر
پاکسازی اولیه داده ها
پاکسازی داده ها یک مرحله بسیار مهم در هر پروژه یادگیری ماشینی است. در دادههای جدولی، تحلیلهای آماری مختلف و تکنیکهای تجسم دادهها وجود دارد که میتوانید برای کاوش دادههای...
جزییات بیشتر
حلقه رویداد چیست؟
حلقه رویداد چیست؟ یک حلقه به طور مداوم در حال اجرا وجود دارد که با حلقه while نشان داده می شود، و هر تکرار این حلقه یک "تیک" نامیده می...
جزییات بیشتر
قوانین ارسال دیدگاه در سایت