k نزدیکترین همسایه (نحوه استفاده از KNN Imputation)

ممکن است یک مجموعه داده دارای مقادیر گم شده باشد. اینها ردیف هایی از داده ها هستند که یک یا چند مقدار یا ستون در آن ردیف وجود ندارد. ممکن است مقادیر به طور کامل گم شده باشند یا ممکن است با یک کاراکتر یا مقدار خاص مانند علامت سوال (“؟”) علامت گذاری شوند. مقادیر ممکن است به دلایل زیادی وجود نداشته باشند، اغلب مختص حوزه مشکل، و ممکن است شامل دلایلی مانند اندازه گیری های خراب یا در دسترس نبودن باشد. اکثر الگوریتمهای یادگیری ماشینی به مقادیر ورودی عددی و یک مقدار برای هر سطر و ستون در یک مجموعه داده نیاز دارند. به این ترتیب، مقادیر از دست رفته می تواند برای الگوریتم های یادگیری ماشین مشکلاتی ایجاد کند. شناسایی مقادیر گمشده در یک مجموعه داده و جایگزینی آنها با یک مقدار عددی معمول است. به این می گویند داده imputing یا از دست رفته داده.
— داده های از دست رفته را می توان نسبت داد. در این مورد، میتوانیم از اطلاعات موجود در پیشبینیکنندههای مجموعه آموزشی برای تخمین مقادیر دیگر پیشبینیکنندهها استفاده کنیم.
یک رویکرد موثر برای برانگیختن داده ها، استفاده از مدلی برای پیش بینی مقادیر از دست رفته است. برای هر ویژگی که دارای مقادیر گم شده است، مدلی ایجاد میشود، و احتمالاً همه ویژگیهای ورودی دیگر را به عنوان مقادیر ورودی در نظر میگیرد.
— یکی از روشهای رایج برای انتساب، مدل K-نزدیکترین همسایه است. یک نمونه جدید با یافتن نمونهها در مجموعه آموزشی «نزدیکترین» به آن وارد میشود و این نقاط نزدیک را برای پر کردن مقدار میانگین میگیرد.
اگر متغیرهای ورودی عددی باشند، میتوان از مدلهای رگرسیون برای پیشبینی استفاده کرد و این مورد کاملاً رایج است. طیف وسیعی از مدلهای مختلف را میتوان استفاده کرد، اگرچه یک مدل ساده k-نزدیکترین همسایه (KNN) در آزمایشها مؤثر بوده است. استفاده از مدل KNN برای پیشبینی یا پر کردن مقادیر از دست رفته به عنوان نزدیکترین همسایه یا انتساب KNN نامیده میشود.
— نشان میدهیم که به نظر میرسد KNNimpute یک روش قویتر و حساستر برای تخمین مقدار از دست رفته ارائه میدهد […] و KNNimpute از روش میانگین ردیف رایج پیشی میگیرد (و همچنین مقادیر از دست رفته را با صفر پر میکند)
پیکربندی انتساب KNN اغلب شامل انتخاب اندازهگیری فاصله (به عنوان مثال Eu clidean) و تعداد همسایگان کمککننده برای هر پیشبینی، فراپارامتر k الگوریتم KNN است. اکنون که با روشهای نزدیکترین همسایه برای محاسبه مقدار از دست رفته آشنا هستیم، بیایید نگاهی به مجموعه دادهای با مقادیر گمشده بیندازیم.
مطالب زیر را حتما بخوانید:

نوشتن حلقه های پایتونیک
نوشتن حلقه های پایتونیک یکی از سادهترین راهها برای شناسایی توسعهدهندهای با پیشینه زبانهای سبک C که اخیرا پایتون را انتخاب کردهاند، این است که ببینید چگونه به عنوان مثال،...
جزییات بیشتر
پلاگین های جاوا اسکریپت در بوت استرپ
Bootstrap JavaScript Plugins بوت استرپ را می توان به دو صورت کامپایل شده یا خام در سایت شما قرار داد. در بوت استرپ 2.2.2، فایل فشرده نشده 59 کیلوبایت و...
جزییات بیشتر
افکار بسته
افکار بسته تبریک می گویم—شما تا آخر راه را طی کردید! زمان برای دادن حتی آن را باز کنید یا از فصل اول عبور کنید. به خودتان دست بزنید، زیرا...
جزییات بیشتر
type.SimpleNamespace – دسترسی به ویژگی های فانتزی
type.SimpleNamespace – دسترسی به ویژگی های فانتزی در اینجا یکی دیگر از گزینههای «باطنی» برای پیادهسازی اشیاء داده در آن وجود دارد 24 این کلاس در پایتون اضافه شد 3.3...
جزییات بیشتر
خط فکری
خط فکری همانطور که به نظر مضحک می آید برای اینکه چگونه روز خود را برنامه ریزی می کنیم و فکر می کنیم که چه کاری انجام دهیم و به...
جزییات بیشتر
Navbar ها در بوت استرپ
Navigation تب دار نه تنها می توانید یک ناوبری تب دار ایجاد کنید، بلکه با استفاده از افزونه جاوا اسکریپت می توانید همچنین با باز کردن پنجره های مختلف محتوا،...
جزییات بیشتر
تماسهای برگشتی
تماسهای برگشتی در فصل 1 ، اصطلاحات و مفاهیم پیرامون برنامه نویسی ناهمزمان در JavaScript را مورد بررسی قرار دادیم. تمرکز ما بر درک صف حلقه رویداد تک رشته ای...
جزییات بیشتر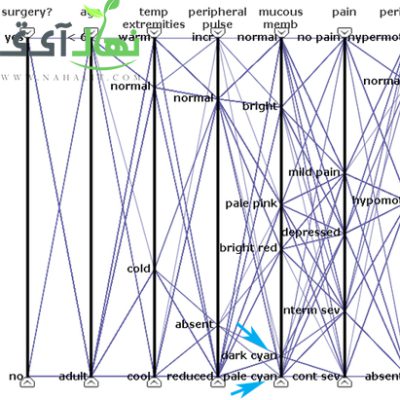
مجموعه داده کولیک اسب(نحوه استفاده از KNN Imputation) و تعیین نزدیکترین همسایه با KNNImputer
مجموعه داده کولیک اسب ما از مجموعه داده کولیک اسب در این آموزش استفاده خواهیم کرد. مجموعه دادههای قولنج اسبی ویژگیهای پزشکی اسبهای مبتلا به قولنج و زنده بودن یا...
جزییات بیشتر
ارزش وعده داده شده
ارزش وعده داده شده قطعاً بعداً در فصل به جزئیات بیشتری در مورد Promises خواهیم پرداخت -- بنابراین اگر برخی از این موارد گیج کننده است نگران نباشید -- اما...
جزییات بیشتر
تاپل – ظروف غیر قابل تغییر
درست مانند لیست ها، تاپل ها نیز بخشی از زبان اصلی پایتون هستند. اما برخلاف لیست ها، اشیاء تاپل پایتون تغییر ناپذیر هستند. این یعنی عناصر را نمی توان به...
جزییات بیشتر
بسیاری از برندهای بزرگ تبلیغات خود را در توییتر به حالت تعلیق در می آورند
برندهای برتر، تبلیغات خود را به دلیل ناتوانی توییتر در شناسایی و متوقف کردن توییت های کودک آزاری، به حالت تعلیق در می آورند دستکم 30 تبلیغکننده بزرگ پس از...
جزییات بیشتر
عوامل اثرگذار بر فناوری اطلاعات
از آنجایی که پذیرش و بهره برداري از فنآوري هاي اطلاعاتی و گام نهادن در مسـیر تعالی اقتصادهاي دانش محور، تا حدزیـادي تحت تـاثیر نگرشـها، باورها و ارزشهاي کاري هیات...
جزییات بیشتر
قوانین ارسال دیدگاه در سایت